
A problem that many publishers, funders, and librarians tell us they face is one of presenting consistent information to their constituents (e.g., boards and other decision-making bodies, research offices, the public). Estimates of outputs or submissions can change from one meeting to the next, especially between quarterly or annual strategy meetings.
This month we focus on the information “lag” and lack of clean and consistent metadata that impact everyone’s ability to get a clear and accurate picture of scholarly publishing.
The measurements change over time
Most studies we come across are snapshots. They take a reading of an index or data source at one point in time and look for patterns. This can provide useful insights, and many are excellent studies. Standard measures – such as Impact Factors – are calculated annually, so snapshots are appropriate in many cases.
Tracking readings over time is less common. Even recurring reports, while maintaining a consistent structure, rarely track like-for-like readings from one year to the next.
We have taken periodic readings of the major indexes since we began our study in summer 2016, and Figure 1 shows some results.

The chart shows the same measures taken (using the same methods and data sources) over successive years. The lines should match, but in more recent years, they diverge. The data varies depending on when the readings were taken.
Notice how, for example, the number of articles published in 2016 varies by 14% depending on when the index was consulted. The data suggest that articles continued to be published after the year they were published in. The trends suggest a catastrophic fall-off in output.
Clearly something is wrong. If publication output had dropped by 90%+ since 2016, every scholarly publishing stakeholder would be both aware and on high alert!
Our industry standard measures are (very) lagging indicators
The reason the divergence illustrated in the chart occurs is because it takes time for the major indexes to count publication outputs. Our industry lacks common infrastructure for gathering basic measures, leaving it instead to the thousands of publishers to deposit information. Even where infrastructure exists – such as CrossRef – publishers are not consistent about how quickly, how much, or even if they deposit information about their outputs. Additionally, the formats and standards they use do not always include the most effective meta data for characterizing publications (case in point: clearly and consistently specifying open access articles in hybrid journals).
When we first started our studies, we noticed this phenomenon and reached out to some of the infrastructure and index providers. They confirmed this was a problem, and some even have schedules modelling when they consider indexes to be “complete” for a given year.
Many other industries have more complete data
One might be tempted to think that the state of our data in scholarly publishing is “par for the course” – surely all industries are like this. However, that is not the case. Figure 2 shows sales of recorded music.
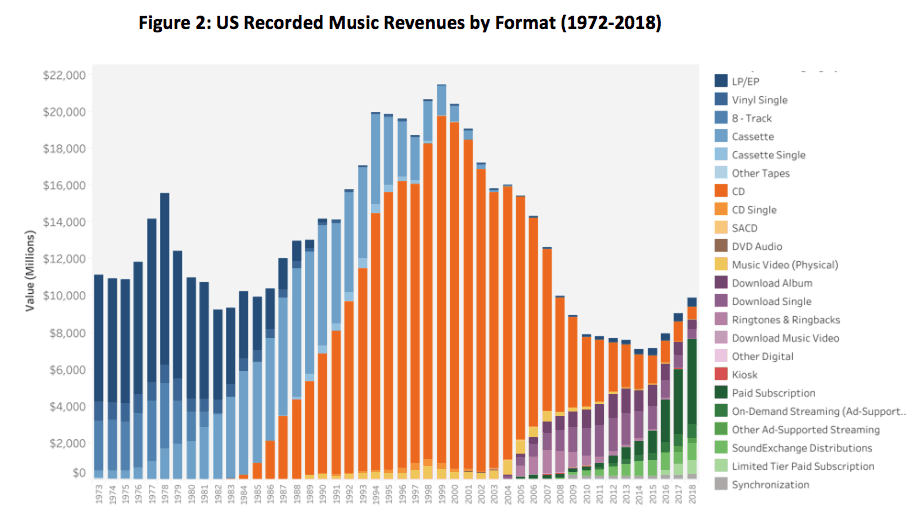
The chart shows inflation-adjusted revenues over time; the colors show format. Working from the left, notice how the blue analog formats (records, cassettes, etc.) are almost completely displaced by orange CD formats. In 2000 we see a steep decline in all sales as Napster and the rise of the Internet wipes two thirds off the market’s value by 2015. Almost 90% of sales in old formats were lost. The road to recovery comes through Internet-based services: downloads (purple) and then streaming (green). Figures are usually released just a few months after year-end, so evidence of movement could be seen within a year, compared with the 3-4 year lag in scholarly publishing data.
Conclusions
Unlike the music industry example above, for scholarly publishing trends-based analysis, you cannot simply take readings from standard data sources. They will be inaccurate and misleading. It also means that people’s headline numbers will change from one year to the next.
We have deliberately not cited a specific source in the first chart above. This is a systemic problem, affecting all sources. We have no wish to risk being seen as being pejorative towards any of them. Some show greater error rates than others, and we have no wish to draw comparisons for the same reason.
We counter the data lag issue through our annual publisher survey, which allows us to match what the indexes say to what people actually see. We are grateful to the many publishers who do share information with us, so we can get as close as we reasonably can to an up to date, accurate view. And, in the spirit of providing a “safe space,” we do not share individual data points or league tables. If you are a publisher that is not currently participating in our survey, we welcome your input and encourage you to join the effort. We would like our annual survey to be seen as providing a valuable service which helps us all to understand our world better.
Basic metadata in our information industry should be like basic hygiene in healthcare. Boring but necessary. If scholarly publishers are stewards of the world’s evidence base, then surely, we need to get our own evidence in order?

TOP HEADLINES
New Penn State open access policy to expand reach of University research – April 30, 2019
“A new open access policy at Penn State, recently endorsed by the University Faculty Senate, will greatly increase public availability of original, peer-reviewed Penn State scholarly research in support of the University’s land-grant mission.”
An Interview with OSTP Director Kelvin Droegemeier – April 30, 2019
“In a recent interview with AIP FYI, White House Office of Science and Technology Policy Director Kelvin Droegemeier weighed in on pressing issues ranging from Europe’s open access push to the National Security Council’s proposed climate science review panel.”
Jisc and Springer Nature renew transformational deal securing Open Access for UK higher education – April 26, 2019
“Jisc and academic publisher Springer Nature have agreed a further ‘read and publish’ agreement that meets the aims of Plan S and offers researchers a funder compliant route to publishing in hybrid journals. Building on a previous arrangement, this agreement limits the costs of publishing all UK articles open access (OA) while maintaining access to all of Springer’s subscription articles.”
Open Access: it’s about more than just journal articles – April 25, 2019
“Research into publication cultures commissioned by VSNU and carried out by Utrecht University Library…provides detailed insight into university output beyond just journal articles.”
Jisc: Perspectives on the open access discovery landscape – April 24, 2019
“Open access discovery tools enable users to find scholarly articles that are available in open form, whether on a publisher’s website or elsewhere. This is a technically-challenging endeavour and also requires a deep understanding of the scholarly communications landscape, the underpinning infrastructure and the needs of widely different stakeholder groups such as researchers, publishers, service providers and the general public.”
Transformative Agreements: A Primer – April 23, 2019
“What’s read-and-publish? Is this contract Plan S compliant? What makes an agreement transformative anyway? What follows is a basic primer on transformative agreements and their characteristics and components.”
Norway and Elsevier Agree on Pilot National Licence for Research Access and Publishing – April 23, 2019
“The Norwegian consortium for higher education and research organized by Unit, and global information analytics business Elsevier today agreed to a pilot national license, providing Norwegian researchers with access to global academic research while making Norwegian research accessible through open access publishing.”
Self-organising peer review for preprints – A future paradigm for scholarly publishing – April 17, 2019
“Preprints – rapidly published non peer reviewed research articles – are becoming an increasingly common fixture in scholarly communication. However, without being peer reviewed they serve a limited function, as they are often not recognised as high quality research publications. In this post Wang LingFeng discusses how the development of preprint servers as self-organising peer review platforms could be the future of scholarly publication.”
Open Access Publishing: New Evidence on Faculty Attitudes and Behaviors – April 15, 2019
“On Friday, Ithaka S+R released the latest cycle of our long-standing US Faculty Survey. This survey has tracked the changing research, teaching, and publishing practices of higher education faculty members on a triennial basis since 2000. Here, we highlight some of the key findings around open access that we expect will be of interest to the scholarly communication community.”
Launch of the Global Alliance of Open Access Scholarly Communication Platforms to democratize knowledge – April 12, 2019
“The Global Alliance of Open Access Scholarly Communication Platforms (GLOALL) was launched with a recognition of the principle that scientific and scholarly knowledge is a global public good essential for the achievement of the UN Sustainable Development Goals.”
Cambridge University Press and the University of California Agree to Open Access Publishing Deal – April 10, 2019
“The University of California and Cambridge University Press have entered into a transformative agreement that will advance the global shift toward an open access future for research. The agreement is designed to maintain UC’s access to Cambridge’s journals, while also supporting open access publishing for UC authors. The partnership is UC’s first open access agreement with a major publisher, and Cambridge’s first such deal in the Americas.”
Cambridge University Press reaches major Open Access agreement with Max Planck Society – April 8, 2019
“Cambridge University Press has reached a major Open Access agreement with Germany’s Max Planck Society (MPG)…The three-year ‘read and publish’ agreement will advance on the traditional subscription model, uniting reading access and open access publishing under one, centrally-administered agreement.”
OA JOURNAL LAUNCHES
April 25, 2019 | “Oxford University Press (OUP) is pleased to announce the launch of in silico Plants, an open access, peer-reviewed, international journal dealing with all aspects of computational plant science. Published on behalf of The Annals of Botany Company, a not-for-profit educational charity established to promote plant science worldwide, [it] launched in April 2019.” | |
April 23, 2019 | Wiley’s New Premier Open Research Next Journals Now Open for Article Submissions | “John Wiley and Sons Inc. is now inviting original research articles for two newly formed open access journals, Genetics & Genomics Next and Neuroscience Next. The journals are led by esteemed Editors-in-Chief who will publish the highest quality, most impactful and groundbreaking research while embracing open research practices.” |
April 18, 2019 | Oxford University Press to Publish NAR Genomics and Bioinformatics | “Oxford University Press (OUP) is pleased to announce that submissions are now open for the new open access title NAR Genomics and Bioinformatics, a sister journal to Nucleic Acids Research (NAR). NAR Genomics and Bioinformatics is an open access and online-only journal that publishes high quality research into genomics and bioinformatics.” |
April 15, 2019 | New Journal: Chinese Chemical Society launches flagship journal – CCS Chemistry | “The Chinese Chemical Society (CCS) is launching its flagship journal, CCS Chemistry, dedicated to serving the global chemistry community. This is the first journal fully owned and published by CCS, one of China’s highly-respected scientific societies…The journal will be Diamond Open Access – free to read and free to publish – with no fees to subscribe or submit.” |
April 9, 2019 | Machine Learning: Science and Technology – a new open-access journal from IOP Publishing | “IOP Publishing is launching Machine Learning: Science and Technology, a new fully open access, multidisciplinary journal devoted to the application and development of machine learning for the sciences.” |